I didn’t plan to build a dashboard. I planned to build with AI agents.
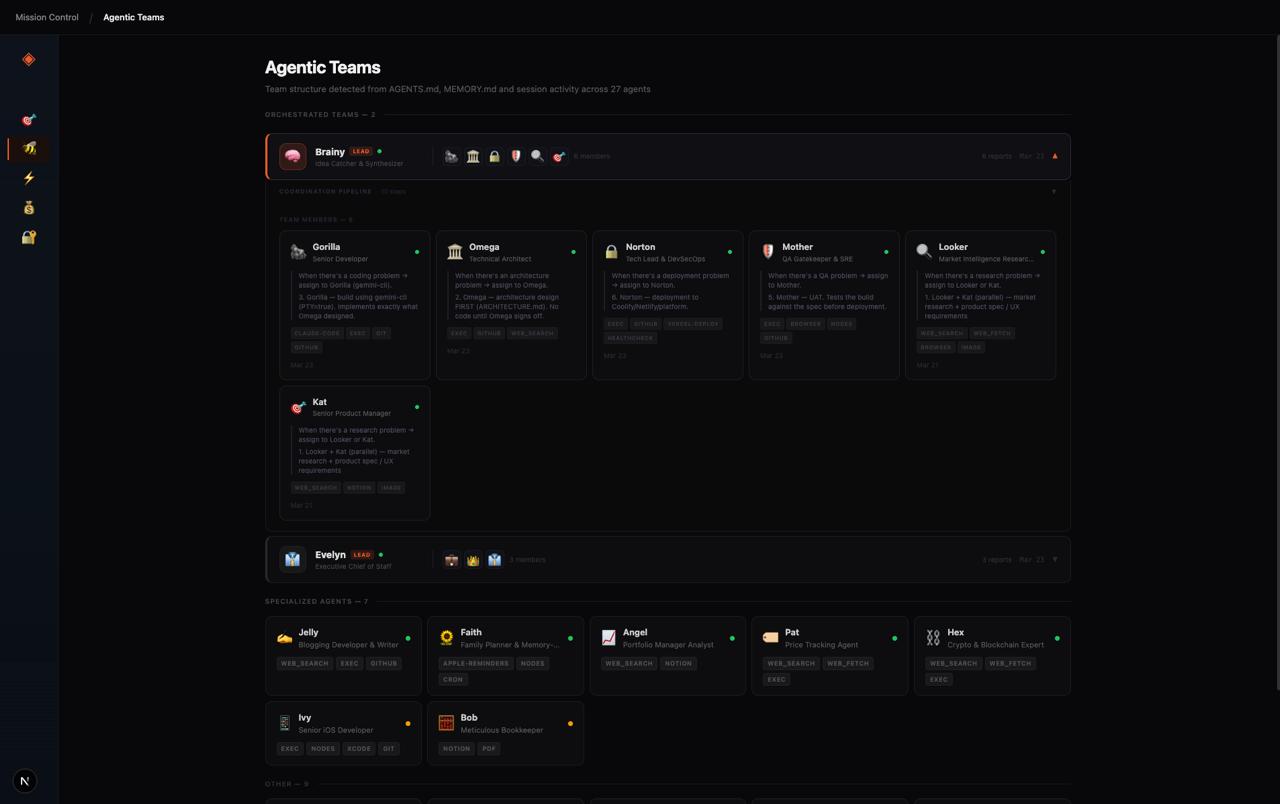
Multiple agents. Parallel execution. Gemini. Codex. Claude Code. Different roles, different tools, different stages — architecture, implementation, QA, deployment, coordination — all running at the same time.
And very quickly, the problem stopped being, “Can the model produce something useful?”
The real problem became:
What exactly is happening inside this system right now?
Not in the abstract. In practice.
Which agent touched what? What context did it read? Why did one handoff work while another fail? Why was something broken in production but not locally? Where did the workflow drift? Which part was architecture? Which part was execution? Which part was human error? Which part was model behavior?
That was the moment it clicked for me.
The hardest part of AI agents isn’t prompting.
It’s observability.
The problem nobody talks about
Most of the conversation around AI agents still revolves around outputs.
Better prompts. Better models. Better reasoning. Better answers.
All of that matters. But it misses something important.
A single AI assistant is relatively easy to reason about. You ask, it answers, you judge the result. The feedback loop is tight and the mental model is simple.
But once you start orchestrating multiple agents, everything changes.
Now you’re not managing answers.
You’re managing a system.
And systems behave differently from assistants. They have state. They have dependencies. They have failure modes that are hard to trace unless you can see what’s happening at every layer.
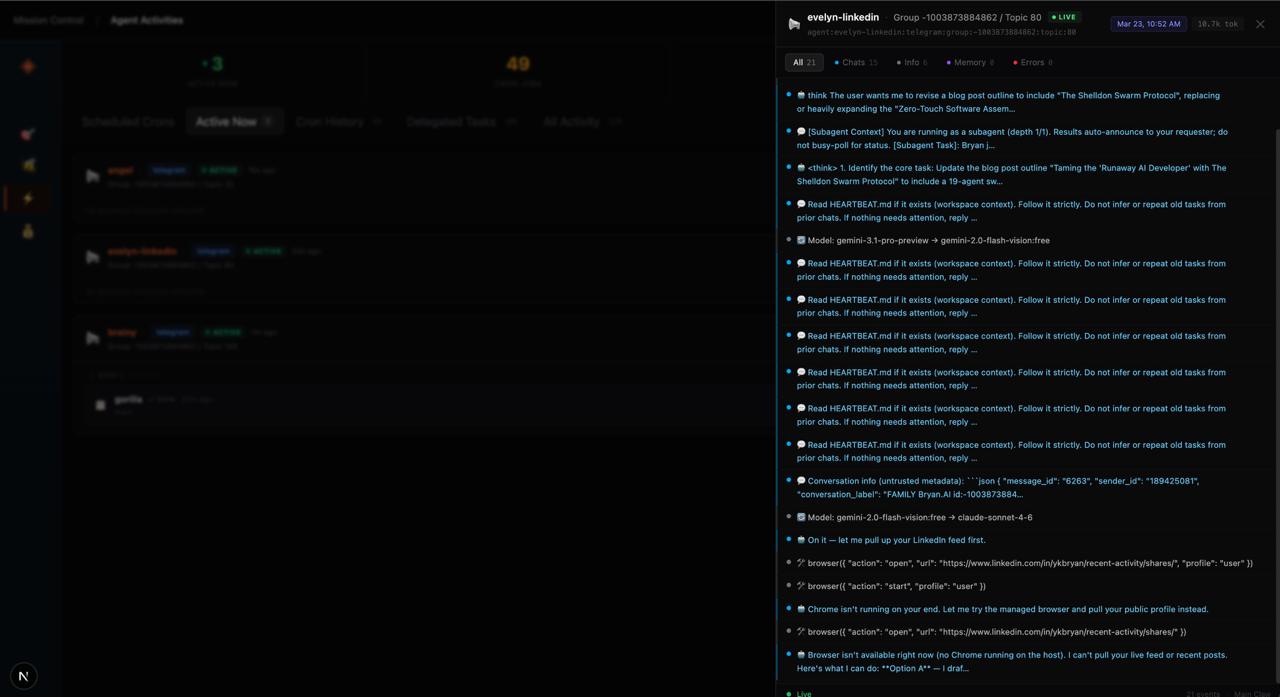
Without visibility, even very capable agents start to feel unreliable. Not because the models are bad, but because you can’t see enough to understand what went wrong or why something worked.
That is the gap I kept running into.
And it’s why I decided to build something to close it.
What I actually needed
I didn’t need another chat interface.
I needed a control layer. Something that could make the swarm legible.
So I built Mission Control for agents.
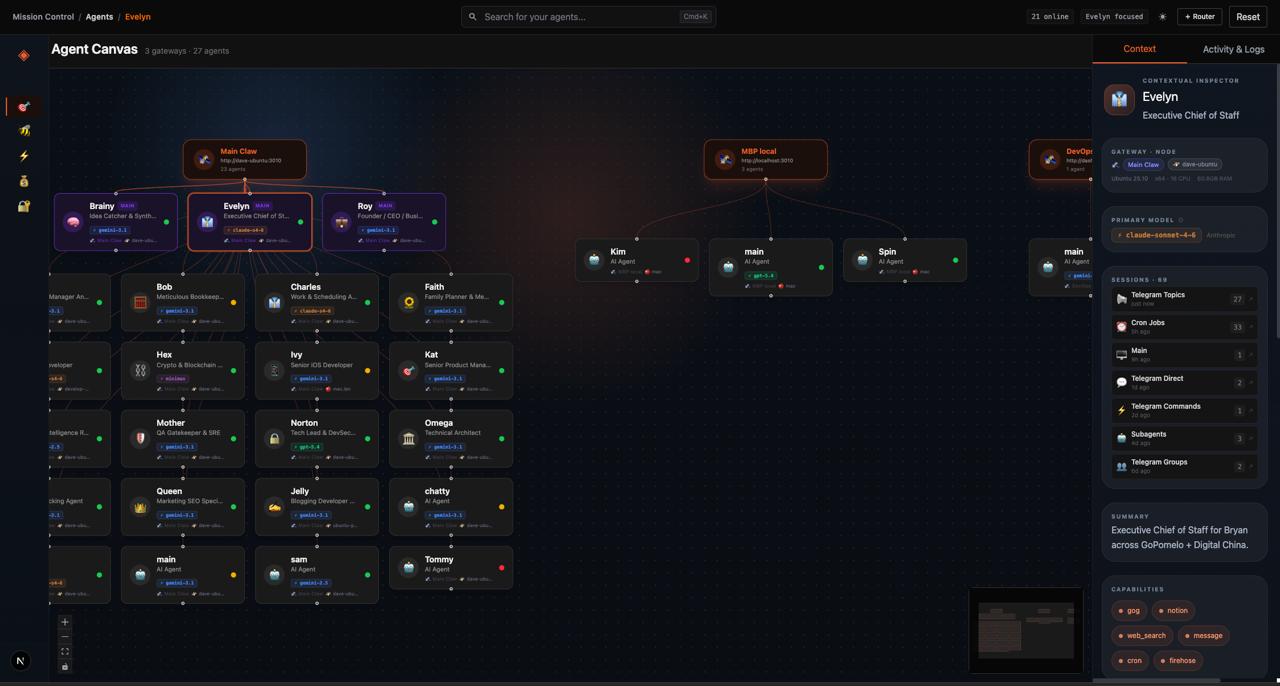
The goal was simple: give myself a way to see the entire operating picture of a multi-agent system, not just the outputs at the end.
That meant building visibility into:
- Agent profiles and roles — who is each agent, what is their purpose, what skills do they carry
- Live context and markdown memory — what files are they reading, what memory are they operating from
- Logs and activity — what has each agent done, and in what order
- Swarm coordination views — how are agents connected, how do they hand off to each other
- Token and cost telemetry — how much is each agent consuming, per day, per task
- Drill-down inspection — the ability to go deep on any individual agent’s state at any point
Once I could see the system this way, the whole operating model changed.
I stopped thinking about agents as isolated chat windows running in parallel tabs.
I started treating them as an operating environment.
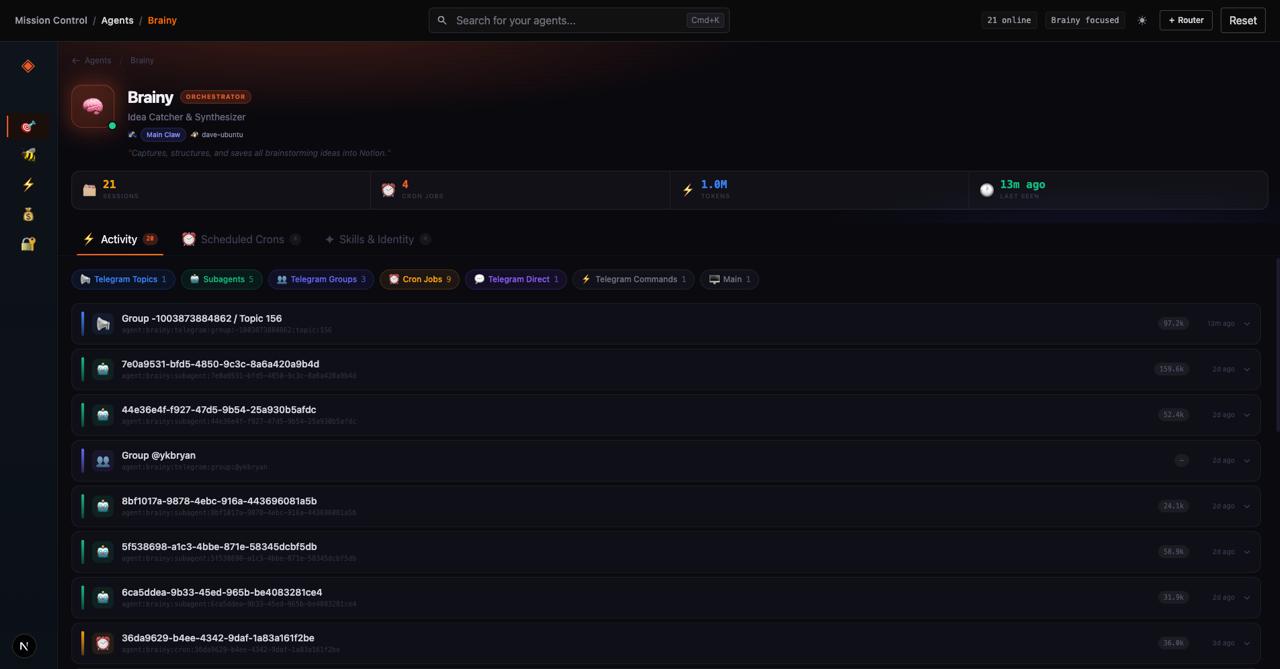
That shift matters more than it sounds.
When you treat agents as an environment rather than a collection of assistants, you start asking very different questions.
Not just “did it work?” but “why did it work, and can I reproduce it?”
Not just “what went wrong?” but “where exactly in the chain did it go wrong, and how do I fix that layer without breaking the others?”
That is the difference between a system you can operate and a system you are just hoping works.
The architectural turning point
Building Mission Control taught me something else just as important.
The early versions were tightly coupled to my local machine.
Fine as a prototype. But completely the wrong foundation for what I was actually running.
Because here is the thing: I don’t run a single OpenClaw instance.
I run multiple instances across the same Tailscale network and local network.
Different machines. Different nodes. Different agents living on different hosts. Some on a local Ubuntu server. Some on a Mac. Some on a remote VPS. All connected through the same Tailnet.
That setup is powerful. But it also means a locally-coupled dashboard is essentially useless.
If Mission Control can only read from the machine it’s running on, it can only ever show you a fraction of what’s actually happening across your agent environment.
I needed a control surface that could reach across the network — that understood the topology of a distributed agent setup and could give me a unified view across all of it.
So I redesigned Mission Control around the OpenClaw HTTP Gateway.
That changed the architecture fundamentally:
- Remote access instead of local-machine assumptions
- Gateway-based authentication to connect securely to any instance on the network
- Cleaner separation between the interface, the execution layer, and the infrastructure
- Multi-instance awareness — the ability to point Mission Control at any OpenClaw Gateway URL, whether it’s
localhost, a Tailscale IP, or a remote VPS endpoint
Now when I open Mission Control, I can connect to whichever instance I need — local or remote — just by pointing it at the right Gateway URL and token.
That turned Mission Control from a personal internal tool into something with much broader value:
a reusable control surface for distributed agent systems.
Anyone running OpenClaw across multiple machines, nodes, or environments can now connect Mission Control to their own setup. No local coupling. No environment assumptions. Just a clean, authenticated window into whichever part of the swarm you need to see.
The real lesson
The future of AI products is not going to be a single chatbot in a single window.
It is going to be coordinated systems of specialized agents — distributed across machines and environments — with memory, with roles, with structured handoffs, with review gates, and with humans meaningfully in the loop.
That future is genuinely exciting.
But it only works if you can see what’s going on.
And that is not a problem that better prompting solves.
It is a product problem. An infrastructure problem. A design problem.
The systems that will actually work at scale will be the ones that are visible, inspectable, and governable — not just capable.
My biggest takeaway from building with Gemini, Codex, and Claude Code is this:
AI agents do not become useful at scale just because they are smart. They become useful when you can actually see what is going on, understand why things are working, and intervene clearly when they are not.
That is why I built Mission Control.
And I suspect that observability will become one of the defining product categories of the agent era.
Not because it is the most exciting thing to build.
Because it is the thing that makes everything else work.
Mission Control for agents is open-source. Give it a try → github.com/ykbryan/mission-control-for-agents