A technology leader’s reflection on the recent shift in AI architecture—moving from vanity metric scaling to true omni-modal problem solving. We’ve spent the last few years treating text as the universal language of AI. It wasn’t. It was just a limitation we had to accept.
The High Cost of the “Frankenstein” Pipeline
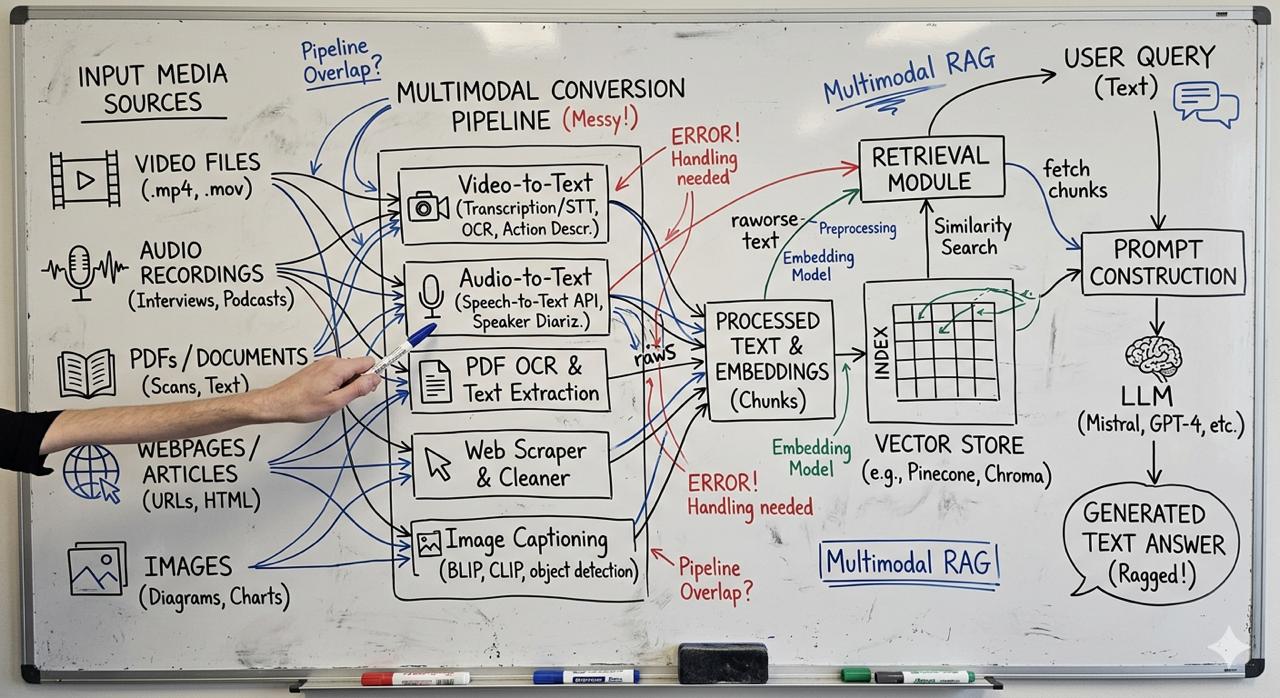 Picture 1 - The High Cost of the “Frankenstein” Pipeline
Picture 1 - The High Cost of the “Frankenstein” Pipeline
If you look at how we’ve built enterprise RAG (Retrieval-Augmented Generation) applications up until this month, the architecture was a mess. If an engineering team wanted to search a library of Zoom recordings or PDFs, they built a Frankenstein pipeline: an OCR microservice for documents, a Speech-to-Text model like Whisper for audio, and Image Captioning for photos. We did all this just to force messy, real-world data into a text embedding model.
But here is the hard truth: text loses context. A transcript strips away the sigh of frustration in an audio clip. A caption loses the trendline on a chart. We were trading nuance for keyword search. When optimizing for “Time to Solve Problems,” adding three middleman models before you even query your database is a losing battle.
Rate of Change: Gemini Embedding 2
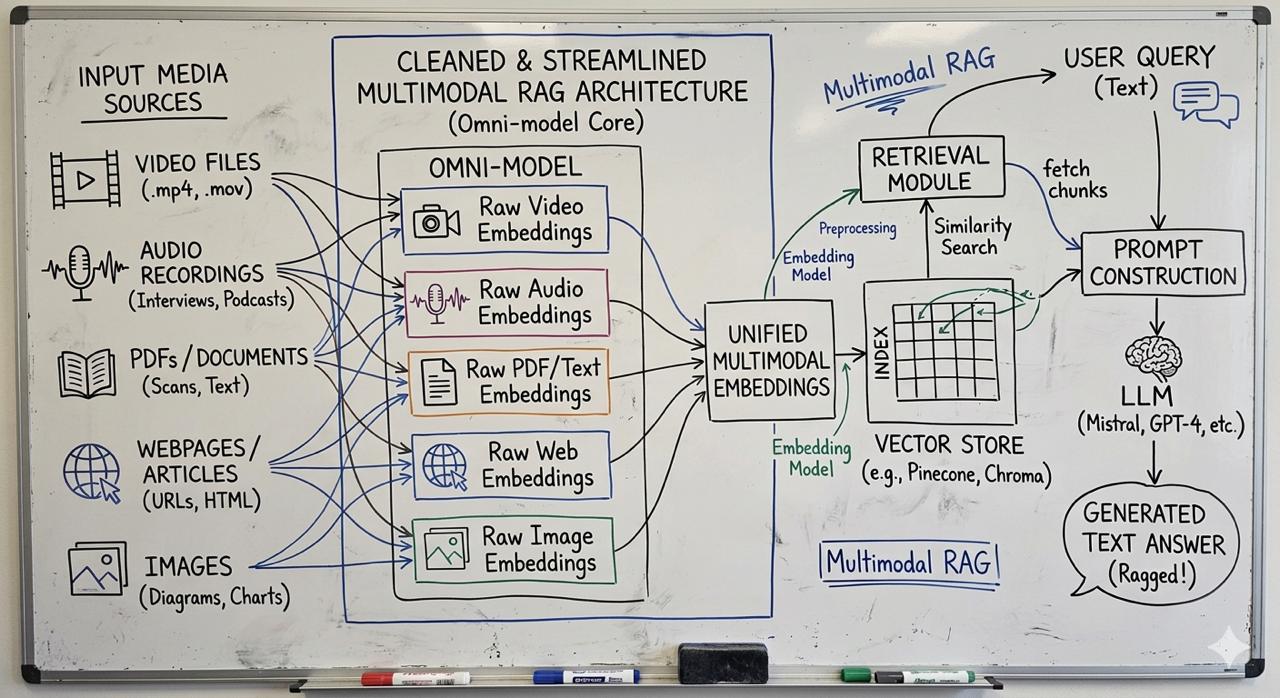 Picture 2 - Before and After: Translating images to text vs Omni-Modal Embeddings
Picture 2 - Before and After: Translating images to text vs Omni-Modal Embeddings
The release of Google’s Gemini Embedding 2 in March 2026 resets this entirely. It is a natively multimodal model. It maps text, video, audio, and images into a single mathematical vector space.
- It listens natively. No transcription needed. It understands tone.
- It sees natively. You can embed a raw 120-second MP4 or an unparsed PDF report directly.
- It simplifies execution. One API endpoint replaces four microservices.
This isn’t just a bump in context window limits (though it does boast an 8,192 token capacity). This is a structural simplification. It allows cross-modal search natively: a user searches with a text query like “a dog barking in a park” and the system returns the actual MP3 or video clip without needing text metadata.
What This Means for Leaders
I’ve always believed that how you do anything is how you do everything. If your data architecture is overly complicated and noisy, your product outcomes will reflect that friction. Focus is a kindness to our engineering teams and a duty to the customers who rely on us.
By removing the “transcription middlemen” from our workflows, we give our teams their time back. We can focus on compounding the right habits—building products that actually understand human intent, creating value, and leaving places better than we found them. The tech industry moves fast, but the companies that will win are the ones that use these leaps not just for vanity AI features, but to genuinely reduce the time it takes to solve a real human problem.
The Caveat: The Walled Garden
Unlike the open-source transparency we saw from players like DeepSeek over the last year, Google is keeping this omni-modal embedding model tightly locked behind their API moat. It is completely closed-weight and exclusive to the Google ecosystem—specifically accessible via Google AI Studio and Vertex AI for enterprise deployments.
For enterprises, this means committing to the Google Cloud infrastructure to leverage this specific architectural advantage. But for organizations already operating at scale, the reduction in pipeline friction and latency is often well worth the admission price.
If you are exploring how to modernize your data pipelines and move beyond the transcription middleman, my team at GoPomelo—a Google Cloud Premier Partner—is actively helping organizations map out these new architectures. Feel free to reach out if you want to see what this looks like in practice.