I’m on holiday currently for a few days, taking a break and this opportunity to delve deeper into DeepSeek-AI’s technical papers, specifically the DeepSeek-V3 technical paper and DeepSeep-V2 technical paper. In this blog, I’ll share my thoughts, what I learned, and the technical aspects I found most interesting. I put the headings below to assess DeepSeek’s core advancements, evaluate its advanced & reasoning-focused model, and explore what these developments mean for AI strategies and startup opportunities.
DeepSeek is a Chinese artificial intelligence (AI) company that develops and releases open-source large language models (LLMs). Founded in 2023 by Liang Wenfeng, DeepSeek’s AI chatbot, DeepSeek-R1, gained significant attention for its performance and cost-effectiveness compared to competitors like OpenAI’s ChatGPT.
TLDR
DeepSeek-V3 is an open-weight mixture-of-experts language model with 671 billion parameters, activating 37 billion per token, and employs native FP8 training to deliver performance comparable to proprietary models like GPT-4, while using just 2.788 million H800 GPU hours for full training. DeepSeek-R1, released in January 2025, builds on V3 by integrating reinforcement learning (RL) techniques—specifically Group Relative Policy Optimization (GRPO)—to specialize in chain-of-thought reasoning and achieve benchmarks on par with OpenAI’s o1, without relying on human-annotated reasoning examples. V3’s multi-head latent attention (MLA) compresses KV caches by 93.3%, boosting throughput 5.76×, while its multi-token prediction (MTP) densifies training signals for improved data efficiency and smoother inference. DeepSeek’s tight integration with NVIDIA hardware treats thousands of GPUs as a unified system, reducing idle time and maximizing utilization through novel accumulation fixes in FP8. Although OpenAI’s o3-mini surpassed R1’s reasoning benchmarks two weeks after R1’s debut, DeepSeek generated substantial hype due to its open accessibility, freely downloadable models, and the reproducibility of its methods—evidenced by a UC Berkeley lab replicating R1-zero techniques on a smaller model for just $30. These developments underscore a shift toward more democratized, cost-efficient AI, setting the stage for B2C and B2B innovation at reduced budgets and signaling an opportune moment to launch AI-focused startups.
DeepSeek and its early hype at 2025
In early 2025, DeepSeek’s rapid ascent through the AI landscape ignited a frenzy of excitement—and anxiety—across the technology and investment communities. Media outlets and social feeds were ablaze with sensational headlines about the model’s open-source weights, sub-$6 million training cost, and benchmark-beating performance. Venture capitalists rushed to back startups leveraging DeepSeek’s architecture, driving up valuations and deal volumes in a matter of weeks. Its mobile app also hits the first place in both Apple and Google’s Playstore. At the same time, traditional AI incumbents and their investors faced palpable panic, scrambling to reassure stakeholders that proprietary models and closed-weight strategies would maintain their competitive moats.
Despite the hype, discerning technology leaders recognized that separating lasting innovations from short-lived buzz was critical.
…models like LLaMA do not use MoE and must activate all 405 billion parameters for each token, leading to 11× more computation per inference step.
DeepSeek V3 Architecture and Innovations
One notably difference to highlight is that there are two distinct AI models - DeepSeek-V3 and DeepSeek-R1. DeepSeek-V3 is a general-purpose large models, which is comparable to OpenAI’s general models GPT-4o. Released at the end of Jan 2025, DeepSeek-R1 is a reasoning model, which applied various algorithmics improvements to optimize its reasoning capabilities and its performance is comparable with OpenAI’s o1. Most of the remarkable technical performances and efficiency were actually discussed first in DeepSeek-V2 technical paper and DeepSeekMath paper (published in Feb 2024). DeepSeek-V3 snitches many engineering techniques together primarily to provide coimpute and training efficiencies. Let’s explore these engineering techniques below:
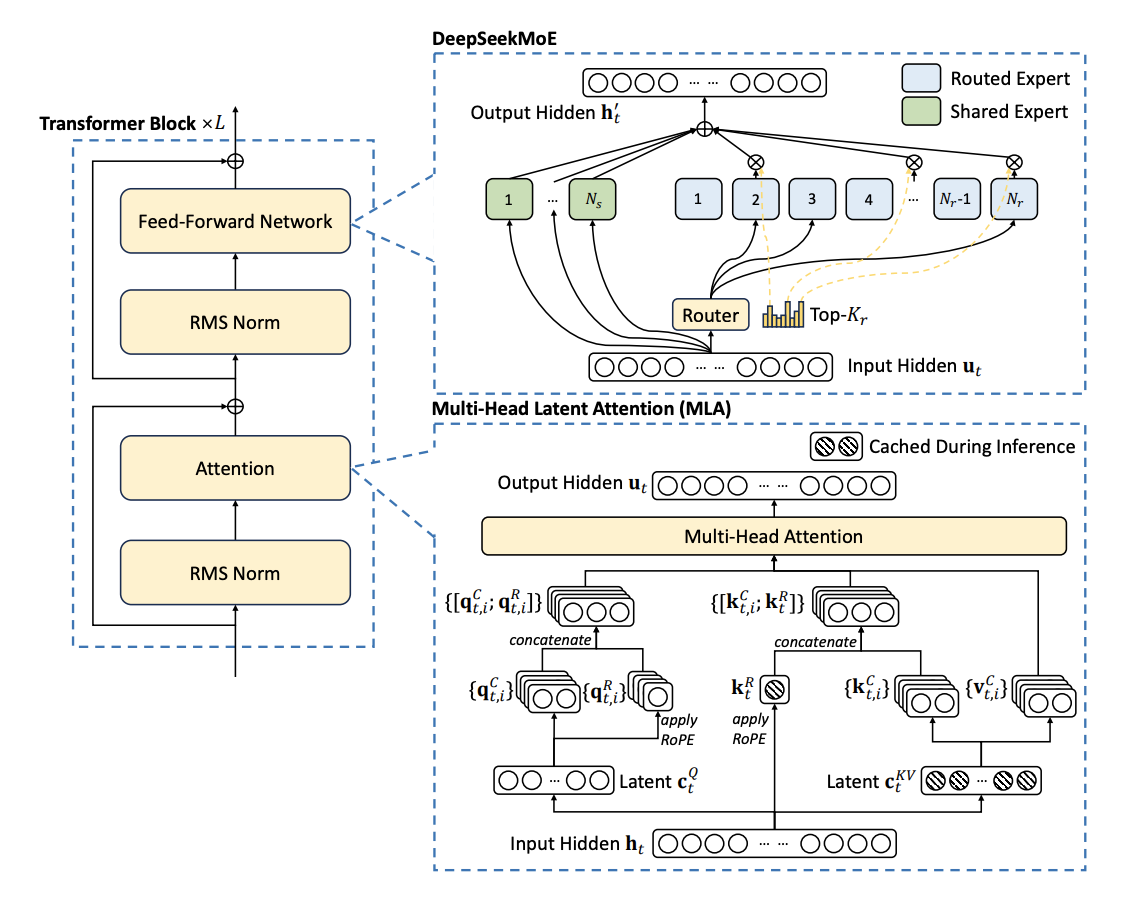 Figure 1 - illustration of the Architecture of DeepSeek-V2 found in the technical paper
Figure 1 - illustration of the Architecture of DeepSeek-V2 found in the technical paper
Mixture-of-Experts and Activation Efficiency
While MoE isn’t a new concept, DeepSeek-V3’s core innovation is its mixture-of-experts (MoE) design - 671 billion total parameters reside in dozens of expert subnetworks, but only about 37 billion parameters are activated per token, reducing compute overhead drastically compared to dense models of similar size. In contrast, models like LLaMA do not use MoE and must activate all 405 billion parameters for each token, leading to 11× more computation per inference step. While MoE architectures have been explored previously, efficient training at this scale is notoriously difficult due to load-balancing challenges; DeepSeek introduces an auxiliary-loss-free strategy that stabilizes expert routing without complex losses, ensuring consistent GPU utilization.
Native FP8 Training with Accumulation Fixes
DeepSeek-V3 trains natively in 8-bit floating point (FP8) format instead of FP16 or FP32, effectively increasing FLOPS (floating point operations per second) while cutting memory consumption in half relative to FP16. To prevent the accumulation of small numerical errors inherent to FP8 arithmetic, DeepSeek engineers introduced periodic accumulation merges back to FP32, a technique termed the “FP8 accumulation fix,” which preserves model quality while enabling thousands of GPUs to work in concert without irrecoverable training instability. With this method, V3’s full training consumed only 2.788 million H800 GPU hours—equivalent to a headline-grabbing $5.5 million—and yet maintained stable loss curves throughout, never requiring training rollbacks.
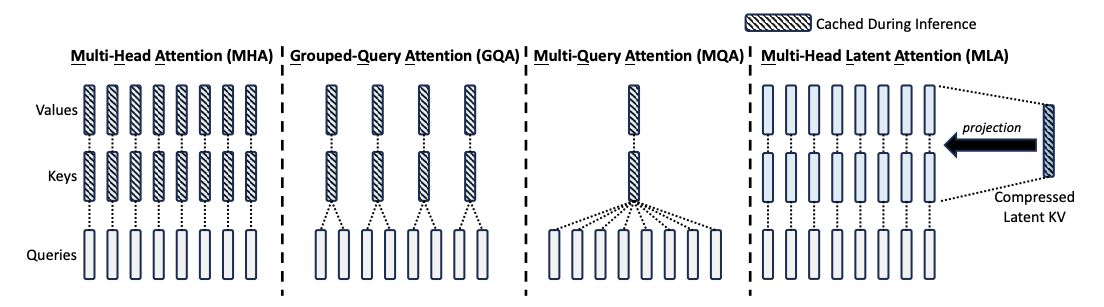 Figure 2 - illustration of Multi-Head Attention (MHA), Grouped-Query Attention (GQA), Multi-Query Attention (MQA), and Multi-head Latent Attention (MLA)
Figure 2 - illustration of Multi-Head Attention (MHA), Grouped-Query Attention (GQA), Multi-Query Attention (MQA), and Multi-head Latent Attention (MLA)
Multi-Head Latent Attention (MLA) and KV Cache Compression
A significant bottleneck for large LLM inference is the key-value (KV) cache stored in VRAM, which can occupy terabytes at high sequence lengths. First introduced in the DeepSeek-V2 technical paper, DeepSeek-V3’s MLA mechanism compresses KV caches into a latent representation and reconstructs them on demand, shrinking KV storage by 93.3% and raising maximum generation throughput by 5.76×. MLA was first validated in DeepSeek-V2 (May 2024) and demonstrates how latent space compression can circumvent VRAM constraints on massive MoE architectures.
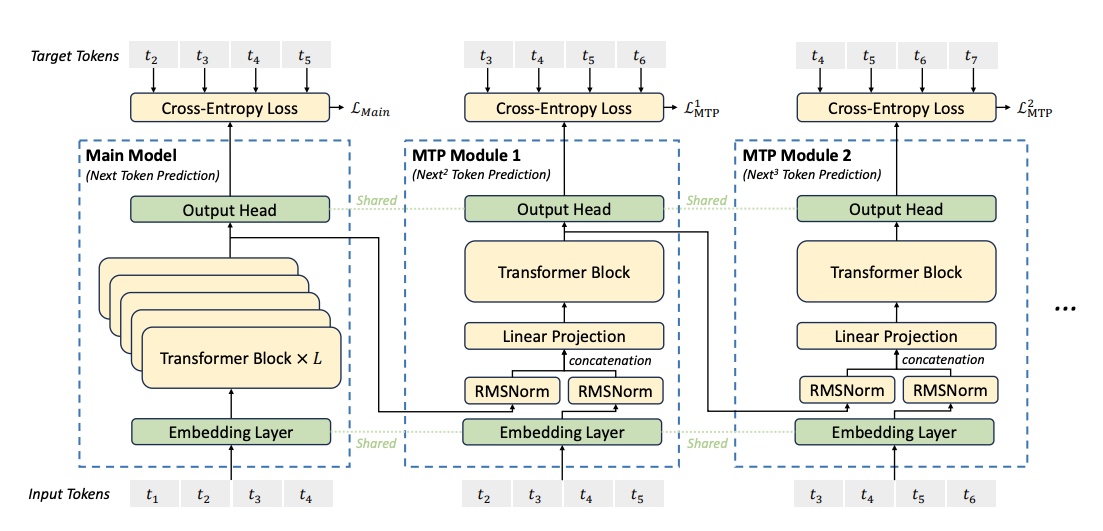 Figure 3 - illustration of Multi-Token Prediction (MTP) implementation, anticipating future tokens at each step, densifies training signal, providing more feedback per step for better data effciency, improves representation planning, allowing model to pre-plan sequences for smoother, more coherent outputs.
Figure 3 - illustration of Multi-Token Prediction (MTP) implementation, anticipating future tokens at each step, densifies training signal, providing more feedback per step for better data effciency, improves representation planning, allowing model to pre-plan sequences for smoother, more coherent outputs.
Multi-Token Prediction (MTP)
Whereas standard causal LLMs predict one token at a time, DeepSeek-V3’s MTP module predicts multiple future tokens simultaneously, densifying the training signal and providing richer feedback per training step. Unlike the other general-purpose large language models, this strategy enhances data efficiency and accelerates convergence while enabling “lookahead” during inference, where the model pre-plans several tokens ahead for more coherent outputs. MTP can also underpin speculative decoding, in which the model proposes token batches to minimize round-trip latency, further reducing sequential processing steps and boosting throughput.
Hardware Integration and System-Level Optimizations
DeepSeek partnered closely with NVIDIA to optimize every layer of the compute stack. By integrating networking, CUDA libraries, and low-level scheduling, they present thousands of GPUs as a single logical device, allowing AI researchers to focus on model design rather than resource management. Even at FP8, GPU utilization peaks at just 34.2% without these system-level improvements; DeepSeek’s unified approach raises utilization closer to peak through pipelining and asynchronous data transfers, reducing idle waits for data movement or caching.
DeepSeek R1: The Reasoning Model
Bringing all these elements discussed above together, DeepSeek-V3 stands out as one of the most impressive general-purpose base models available on the market, and it has maintained its relevance for quite some time now (June 2025). However, the release of the DeepSeek-R1 model is what truly made waves. While most LLMs can be enhanced by prompting them to think step-by-step, reasoning models differentiates themselves by being specifically trained to break-down complex problems and engage in a deep, paragraph-length reasoning steps. This focused training allows them to tackle challenging tasks more effectively than traditional prompting methods.
Evolution from V3 to R1 and Release Context
DeepSeek-R1 launched at the end of January 2025 as a reasoning-optimized variant of DeepSeek-V3, targeting benchmarks where chain-of-thought and multi-step reasoning are critical—particularly math and coding tasks. While many practitioners achieve better reasoning by prompting general models to think step-by-step, R1 was trained specifically to break down problems paragraph by paragraph, similar to OpenAI’s o1 which demonstrated chain-of-thought prowess in September 2024.
 Figure 3 - illustration of RLHF can be performed traditionally on Amazon SageMaker
Figure 3 - illustration of RLHF can be performed traditionally on Amazon SageMaker
Pure Reinforcement Learning and Group Relative Policy Optimization (GRPO)
Unlike conventional RLHF or RLAIF pipelines that rely on human or AI-generated feedback, DeepSeek-R1-zero (the initial iteration) used a purely rule-based grading system: the model’s final outputs on math and coding problems were scored based on accuracy and formatting with simple heuristics. These scores were then fed into a newly proposed RL algorithm called Group Relative Policy Optimization (GRPO), which allowed the model to learn chain-of-thought behaviors without external expert examples. Over thousands of RL steps, R1-zero exhibited emergent reasoning skills—extended chains of thought and self-corrections akin to an “Aha moment” when it recognized mistakes. You will be able to see more technical details in their technical paper.
 Figure 4 - a snapshot of the technical equation of GRPO in DeepSeek-R1 technical paper
Figure 4 - a snapshot of the technical equation of GRPO in DeepSeek-R1 technical paper
Cold-Start Fine-Tuning to Address Readability
Early versions of R1-zero mixed English and Chinese arbitrarily in its reasoning steps, suffering from poor readability for international users (switching between English and Chinese at random). To resolve this, DeepSeek introduced a cold-start fine-tuning phase, stated in the technical paper using structured reasoning examples to nudge the model toward consistent English-based chains-of-thought. The fine-tuned R1 matched or exceeded o1 on multiple standardized math and coding benchmarks, with outputs far more comprehensible to global developers.
Performance and Benchmark Comparisons
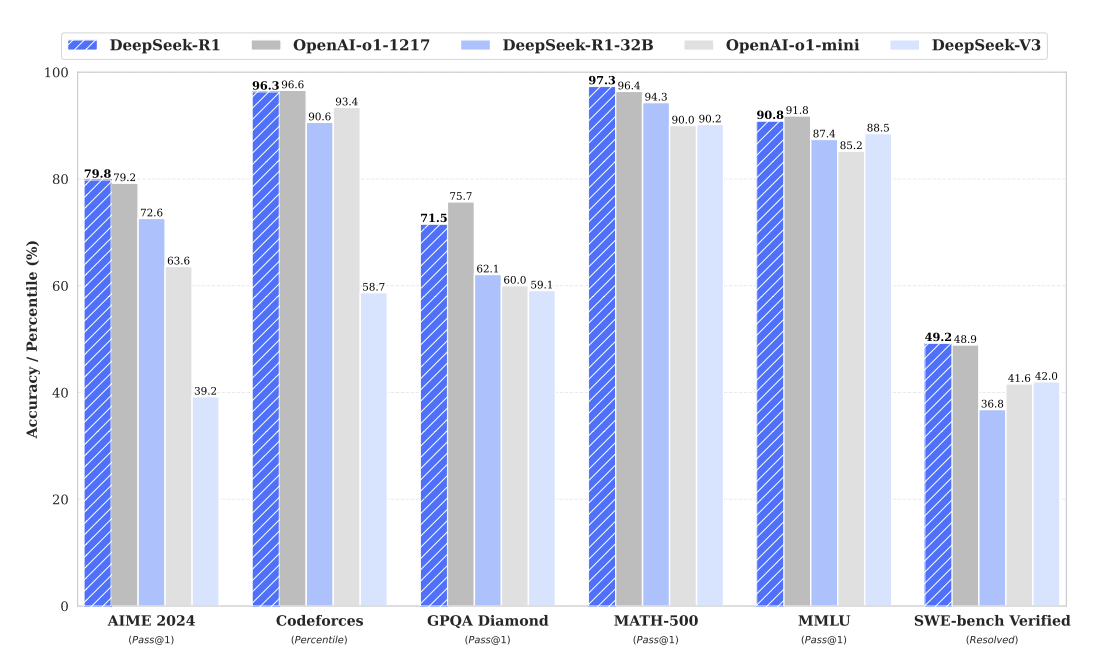 Figure 5 - Benchmark performance of DeepSeek-R1 found in DeepSeek-R1 technical paper
Figure 5 - Benchmark performance of DeepSeek-R1 found in DeepSeek-R1 technical paper
DeepSeek-R1 vs. OpenAI o1 and o3-mini
On major math and coding tasks like GSM8K and HumanEval, DeepSeek-R1’s zero-shot reasoning performance closely paralleled OpenAI’s o1, despite R1’s reliance on pure RL training without human-labeled chain-of-thought examples. However, merely two weeks after R1’s release, OpenAI introduced o3-mini — an updated reasoning model that outperformed both o1 and R1 on many benchmarks — demonstrating how rapidly the frontier is shifting.
Community-Driven Accessibility and Reproducibility
DeepSeek’s decision to open-source R1 (including intermediate checkpoints) and host it freely on platforms like Hugging Face led to swift community adoption and experimentation. Within a month, a UC Berkeley research group applied R1-zero’s reinforcement learning techniques to a smaller model, achieving comparable reasoning on a $30 GPU budget, underlining DeepSeek’s commitment to reproducibility and democratization. This accessibility fueled widespread excitement, particularly among startups seeking cost-effective alternatives to closed-weight models from OpenAI, Anthropic, and Google.
… suffering from poor readability for international users (switching between English and Chinese at random). To resolve this, DeepSeek introduced a cold-start fine-tuning phase…
Cost Efficiency and Hype Dynamics
Training Cost Breakdown and Efficiency
DeepSeek’s claim of $5.5 million total training cost for V3 (and downstream R1 phases) referred only to final-phase compute on H800 GPUs. Early-stage pretraining and algorithmic optimizations kept cumulative expenditures well below the headline figure, making it feasible for smaller research labs to replicate core methods. The cost-per-billable-token and overall frame-per-dollar metrics put V3 and R1 among the most efficient contemporary models, challenging narratives that only deep-pocketed incumbents can lead AI progress.
Hype Factors Beyond Pure Algorithms
While DeekSeek-R1’s algorithmic breakthroughs were noteworthy, a significant portion of its hype stemmed from the fact that the model and its associated papers (e.g., “DeepSeekMath” from February 2024) were readily downloadable, and its app was free to use without restrictions. By contrast, OpenAI’s o1 and o3-mini are accessible only via API, with usage fees that constrain large-scale experimentation. DeepSeek’s zero-cost barrier attracted a broad user base almost overnight, amplifying media coverage and discussions about potential shifts in global AI power balances.
Implications for AI Landscape and Startups
Democratization of High-End AI
DeepSeek’s approach demonstrates that high-performance LLMs with state-of-the-art reasoning can be developed transparently at a fraction of traditional costs. By open-sourcing both V3 and R1 architectures, DeepSeek has blurred the lines between academic research and industry labs, inviting academic and indie contributions to an ecosystem once dominated by proprietary incumbents. This democratization accelerates new use cases in B2C and B2B, from personalized assistants to domain-specific reasoning services, without requiring multi-million-dollar budgets.
Opportunity for New Entrants
As GPU workloads become more efficient—thanks to FP8 training, MoE, MLA, and MTP—smaller teams can deliver competitive AI products with fewer resources. The fact that a group of researchers at UC Berkeley reproduced a R1-like reasoning model on a $30 compute budget highlights how accessible high-end research has become. For senior technology leaders evaluating AI strategies, this signals that the competitive moat around large LLMs is narrowing: innovation now centers on software optimizations, integration, and specialized fine-tuning rather than raw parameter count alone. The best time to build an AI startup is arguably now, as barriers to entry continue to fall and foundational models like DeepSeek-V3 and R1 set new benchmarks for open collaboration.
What have I learnt so far
DeepSeek’s dual approach — rolling out an efficient, MoE-based V3 model alongside a reasoning-focused R1 model — shows that open-weight, cost-effective LLMs can truly rival the big closed-source players. Their innovations in FP8 training, MoE routing, KV cache compression with MLA, and multi-token prediction offer exciting blueprints for the next generation of AI infrastructure. What really caught my attention is R1’s pure reinforcement learning (RL) approach to chain-of-thought training, which proves that clever algorithms can sometimes beat just scaling up hardware. This resonates well with me because pure RL has been a key focus in research labs for years — DeepMind’s AlphaGo, for example, used thousands of self-play games to beat the world’s top Go player back in 2016. Then in 2019, OpenAI showed RL’s potential again by training a robotic hand to solve a Rubik’s Cube and by beating top human players in DOTA 2. Even though OpenAI’s o3-mini eventually surpassed R1 on some reasoning benchmarks, DeepSeek’s open, transparent pipeline reshapes how we think about democratizing AI.
The best time to build an AI startup is arguably now, as barriers to entry continue to fall and foundational models like DeepSeek-V3 and R1 set new benchmarks for open collaboration.
For anyone leading tech teams, the DeepSeek story is a great reminder to focus on compute efficiency, embrace open research, and invest in specialized reasoning to stay ahead in this fast-moving AI space.